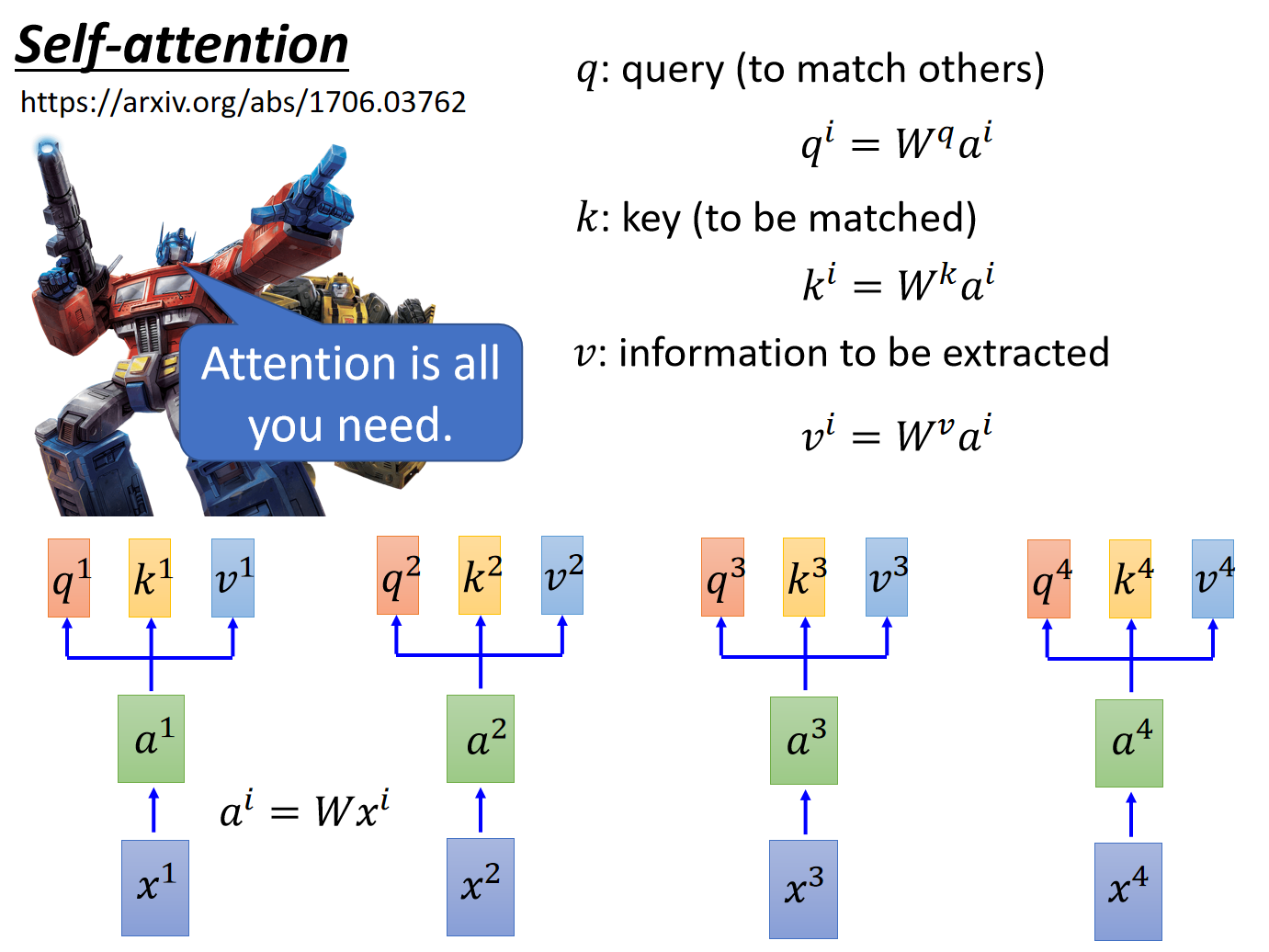
self-attention
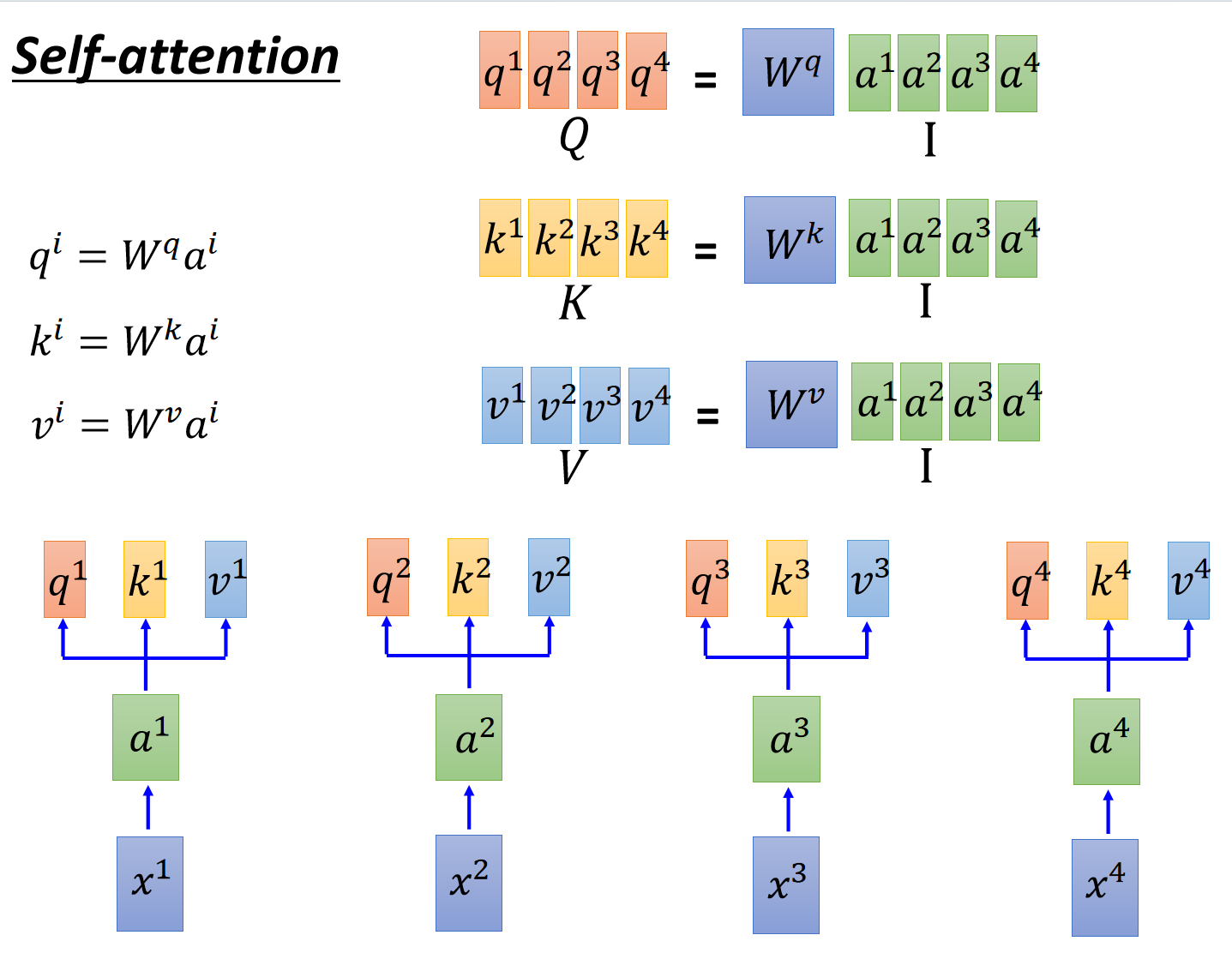
其实就是三个矩阵,
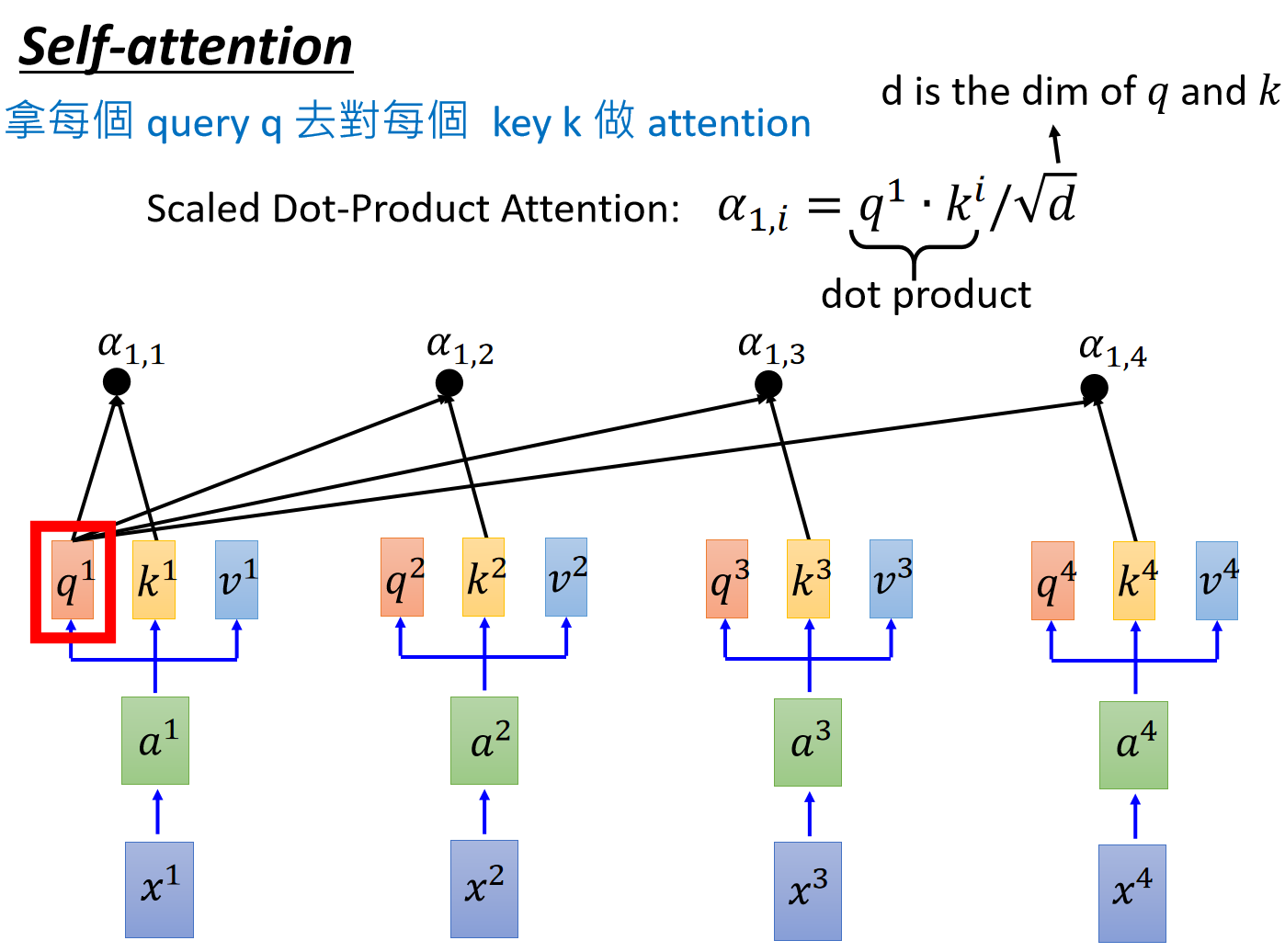
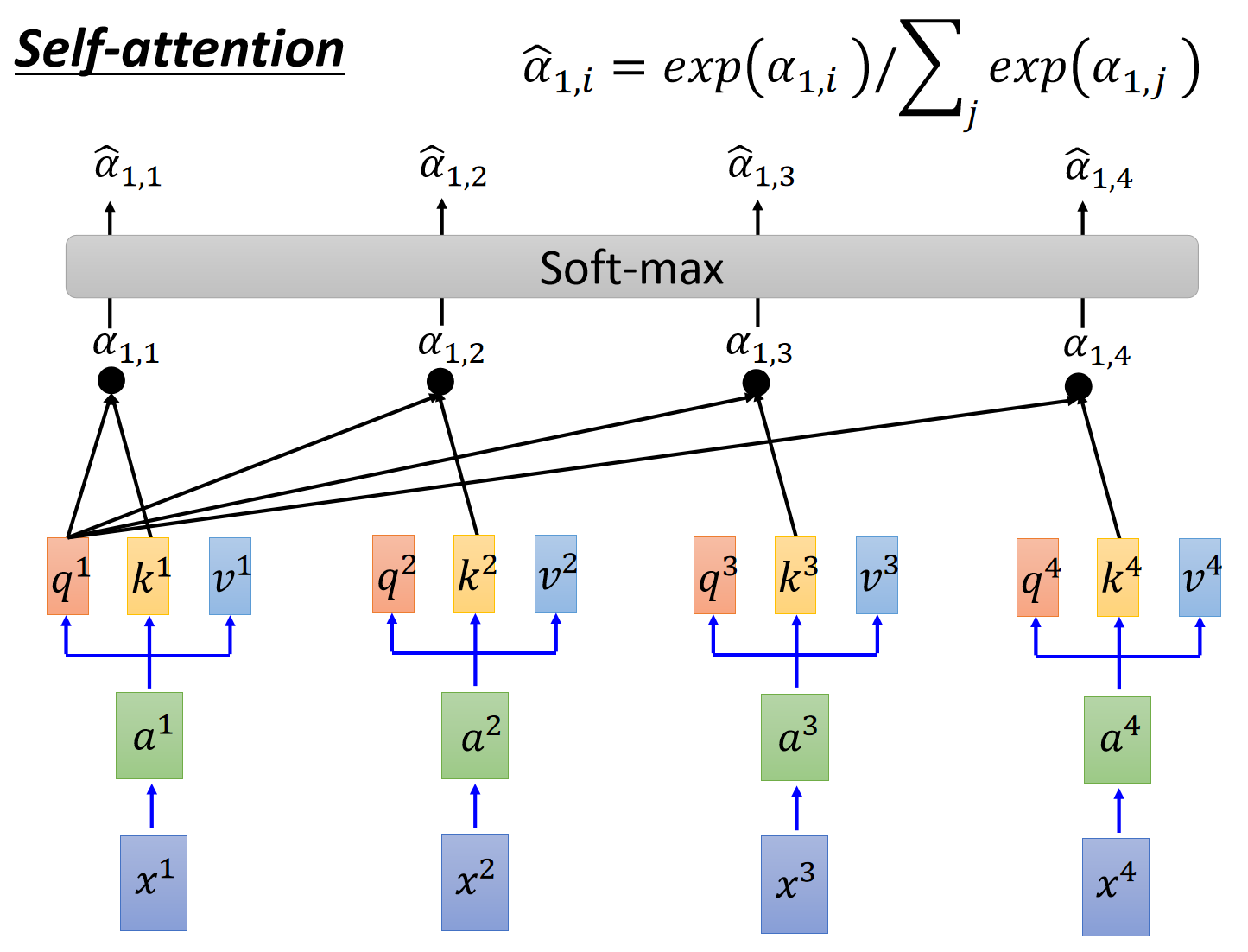
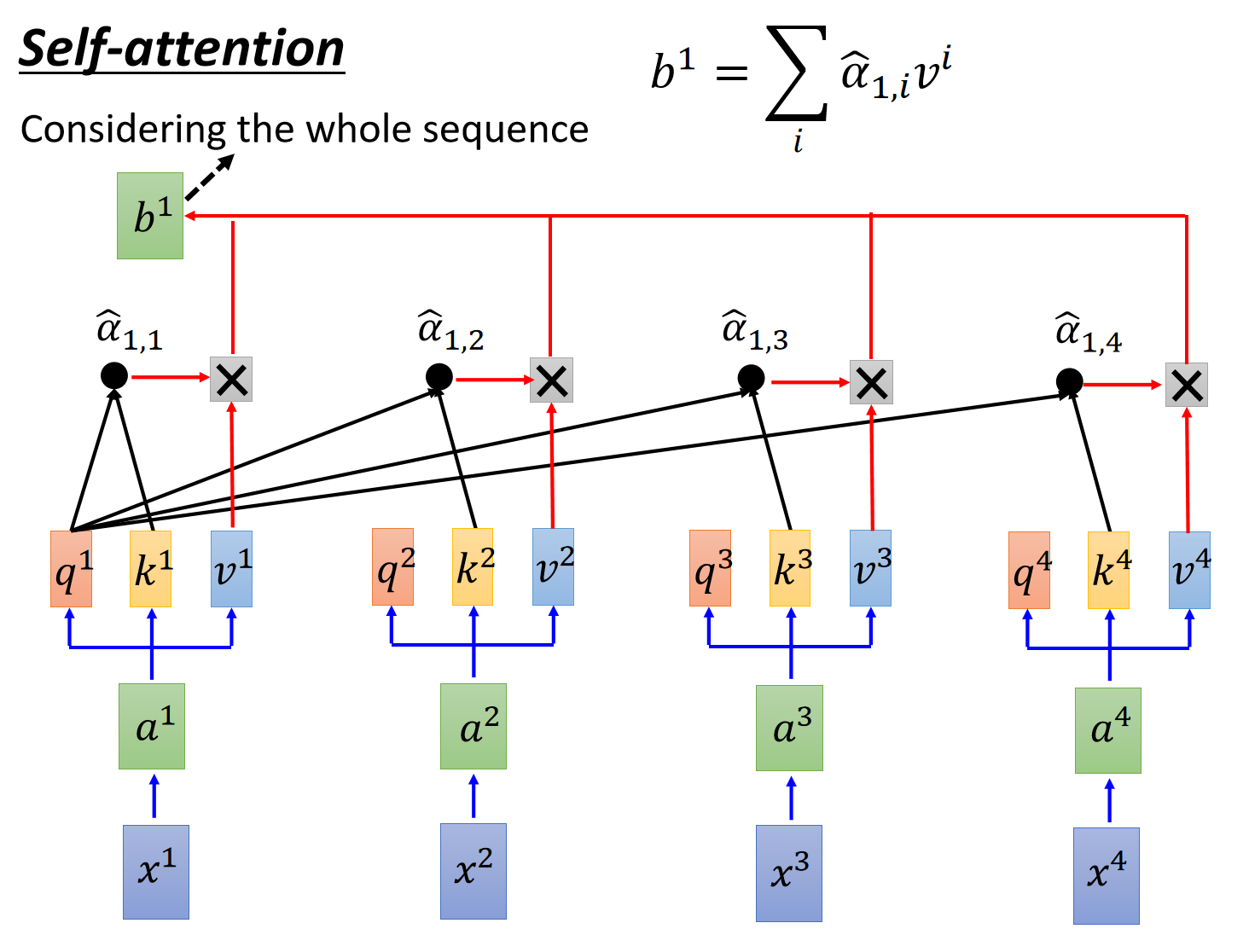
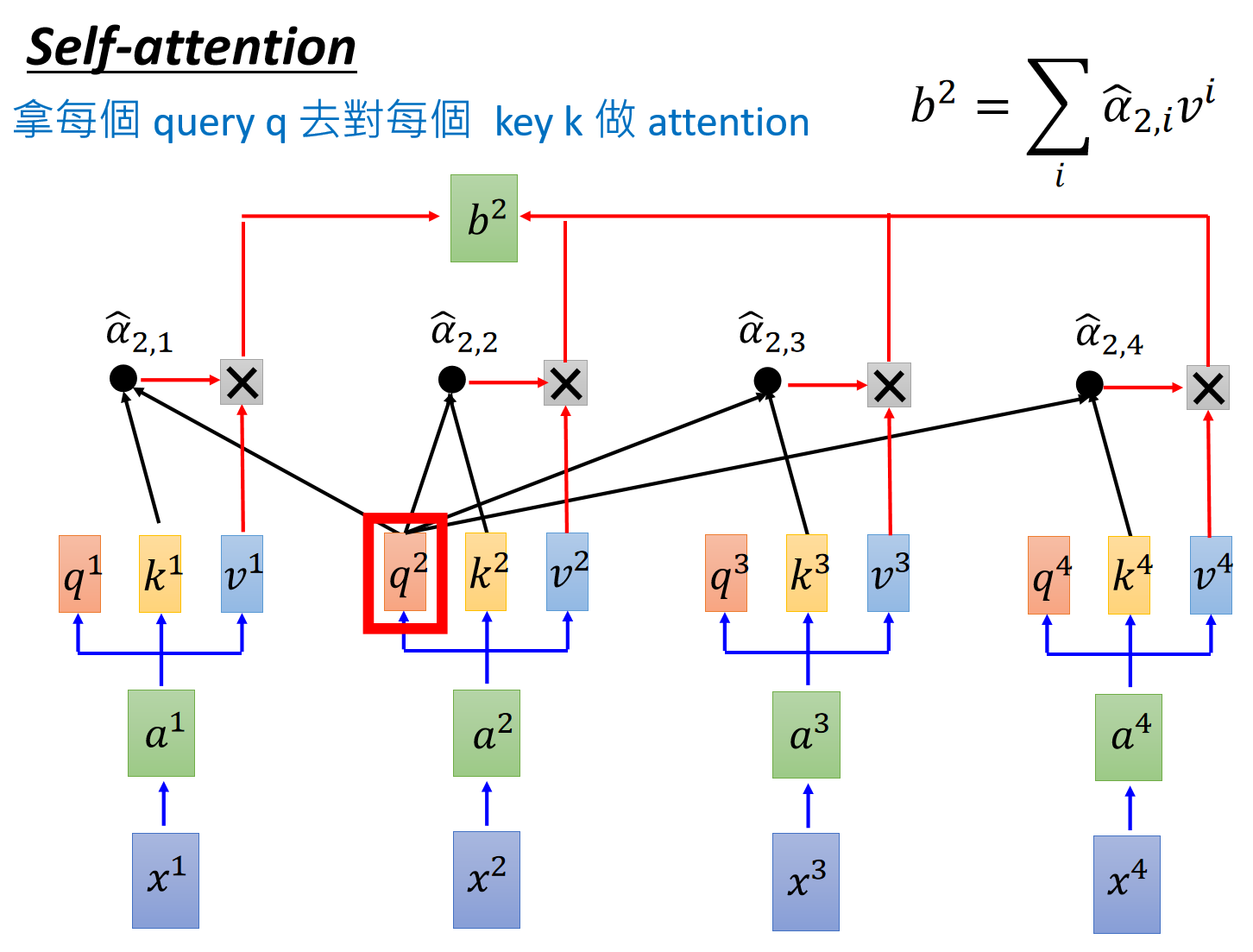
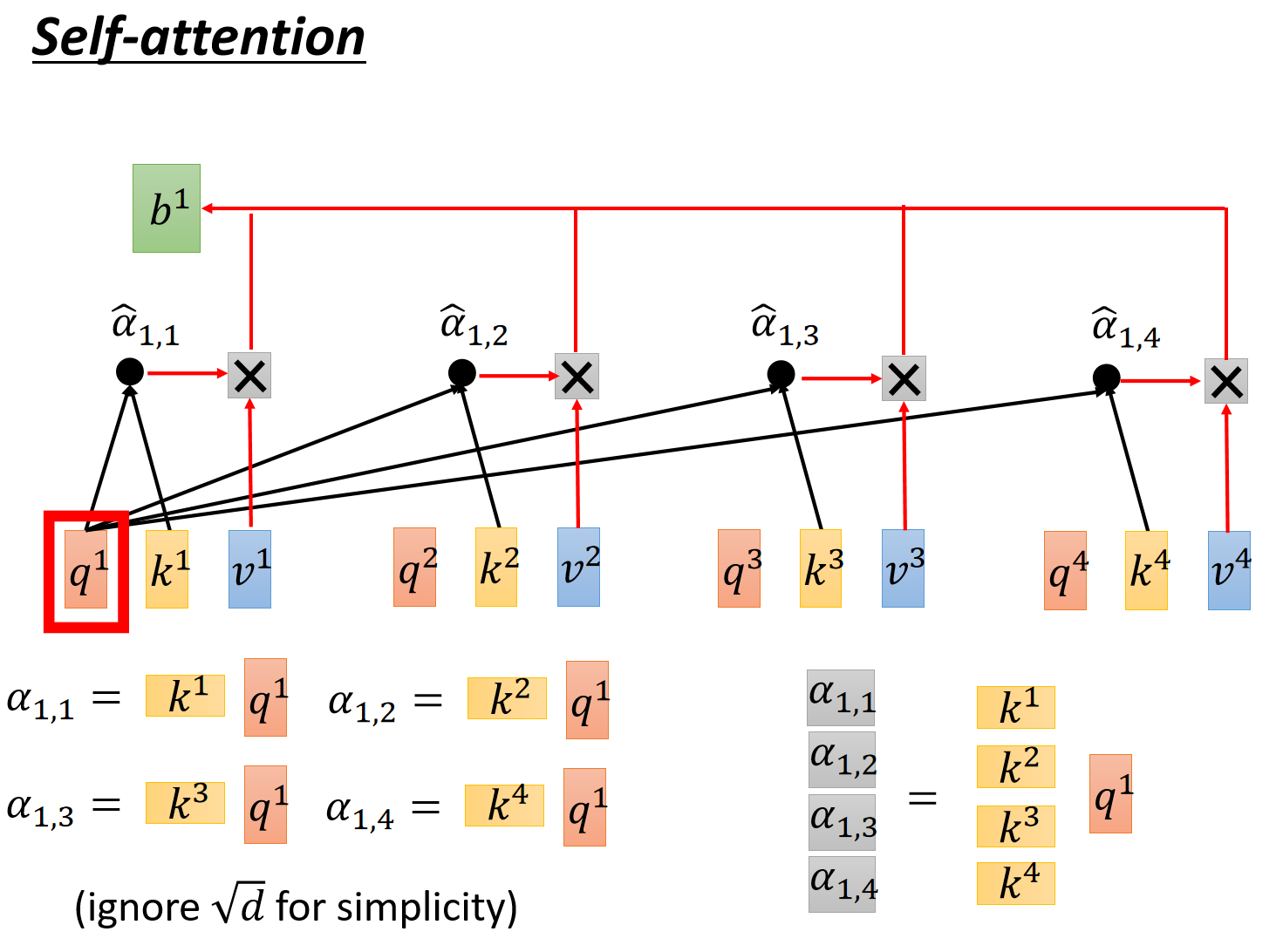
拿到attention scores以后呢,既然已经知道了token的之间的“关联性”,再分别和
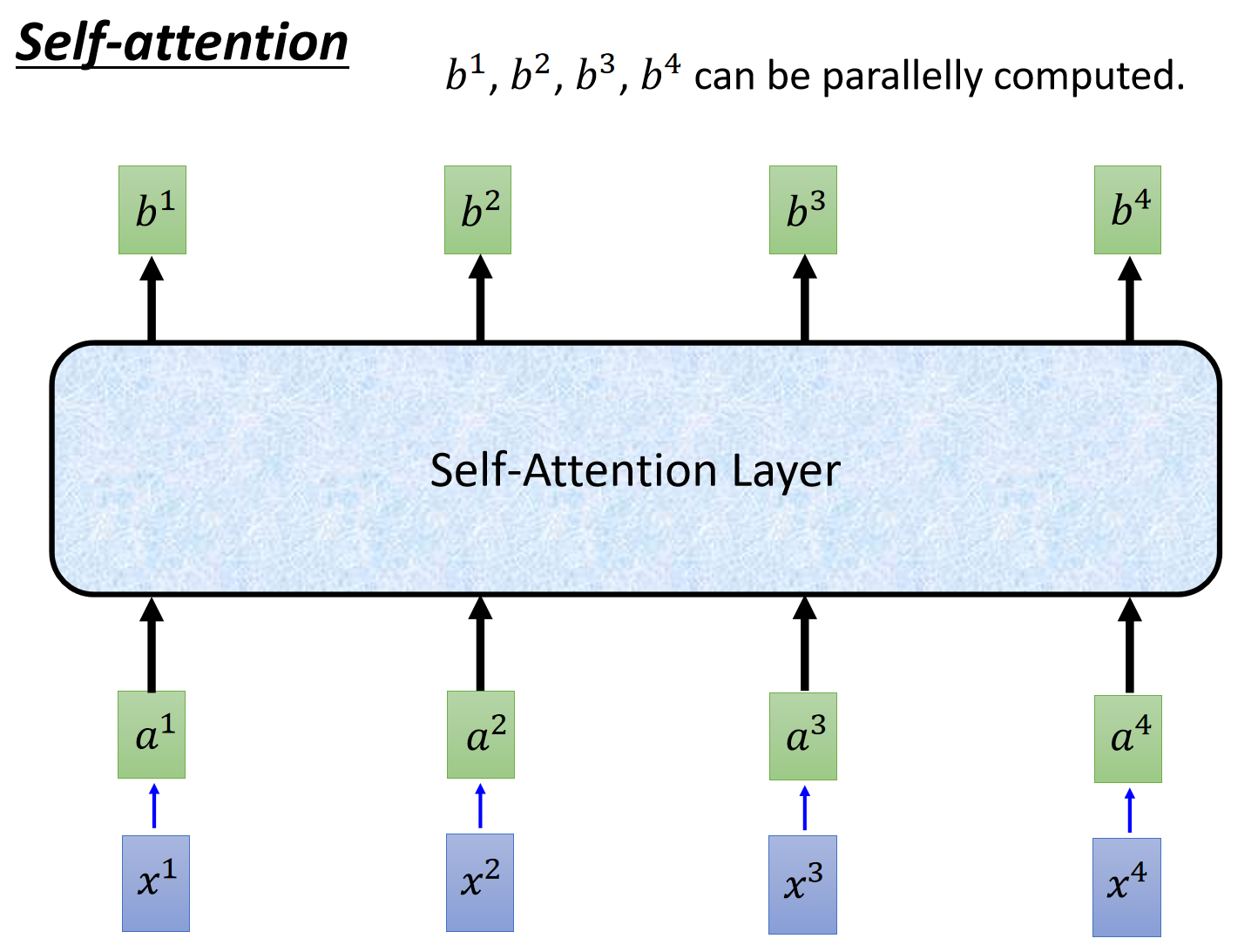
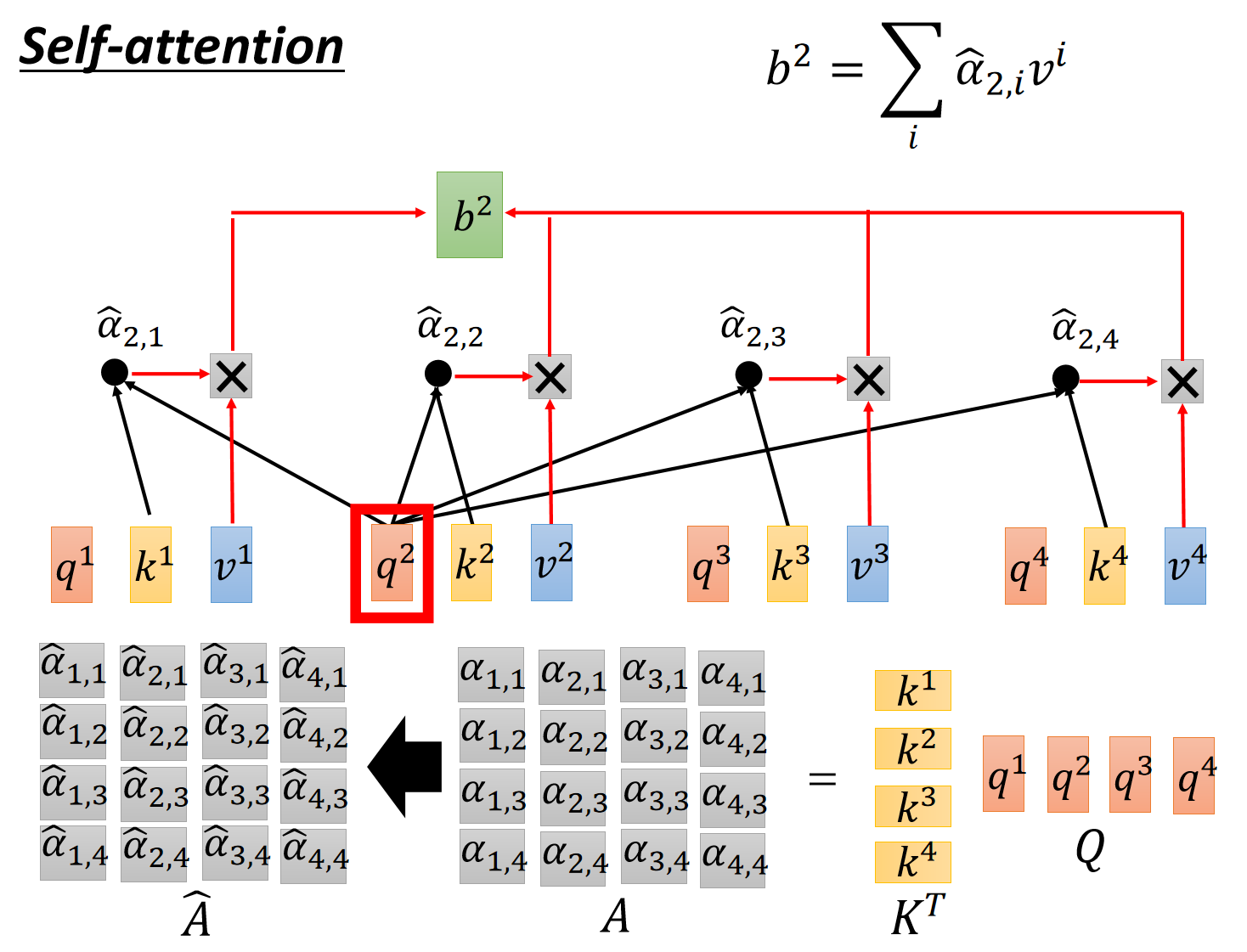
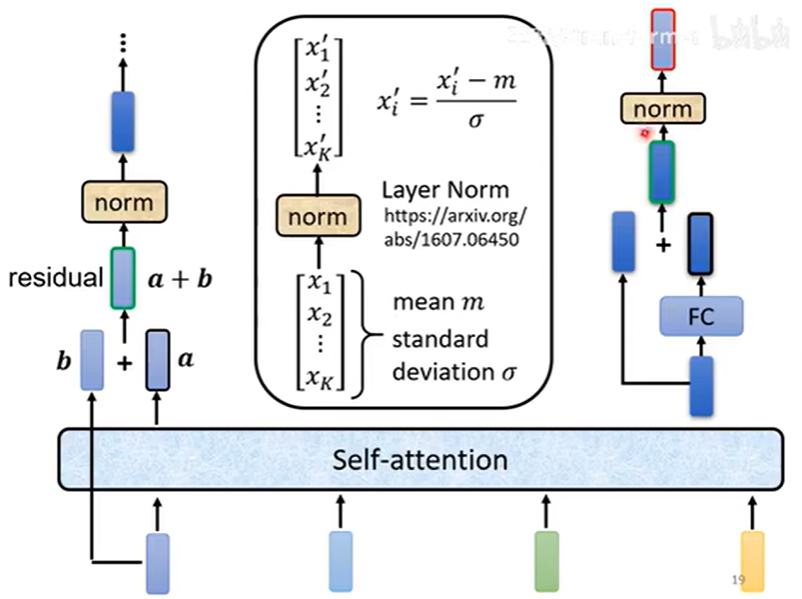
值得注意的是,上述操作是可以通过矩阵表示的。这里直接给李宏毅老师的ppt吧,很清晰。
multihead-attention
其实就是把前面一小节得到的
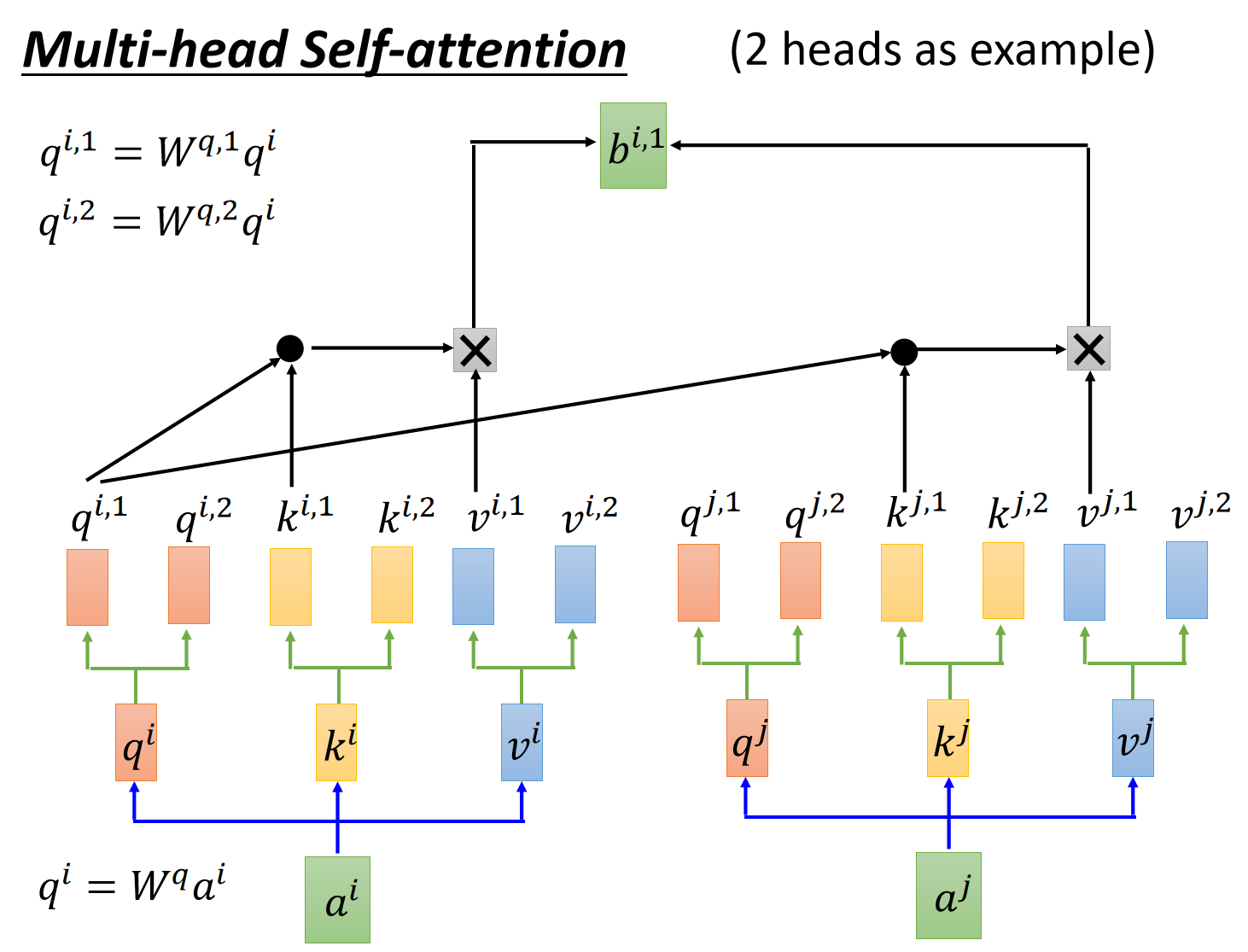
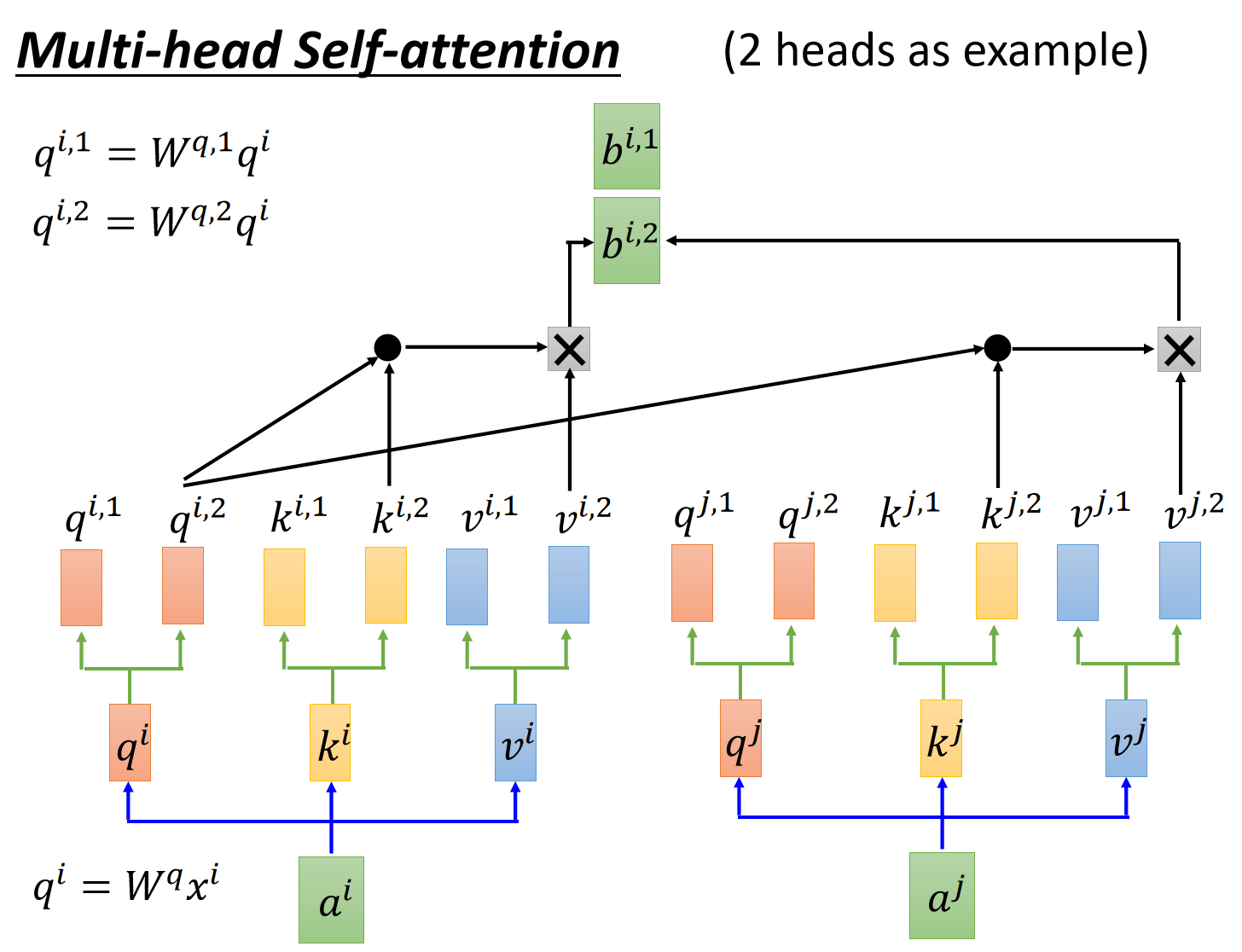
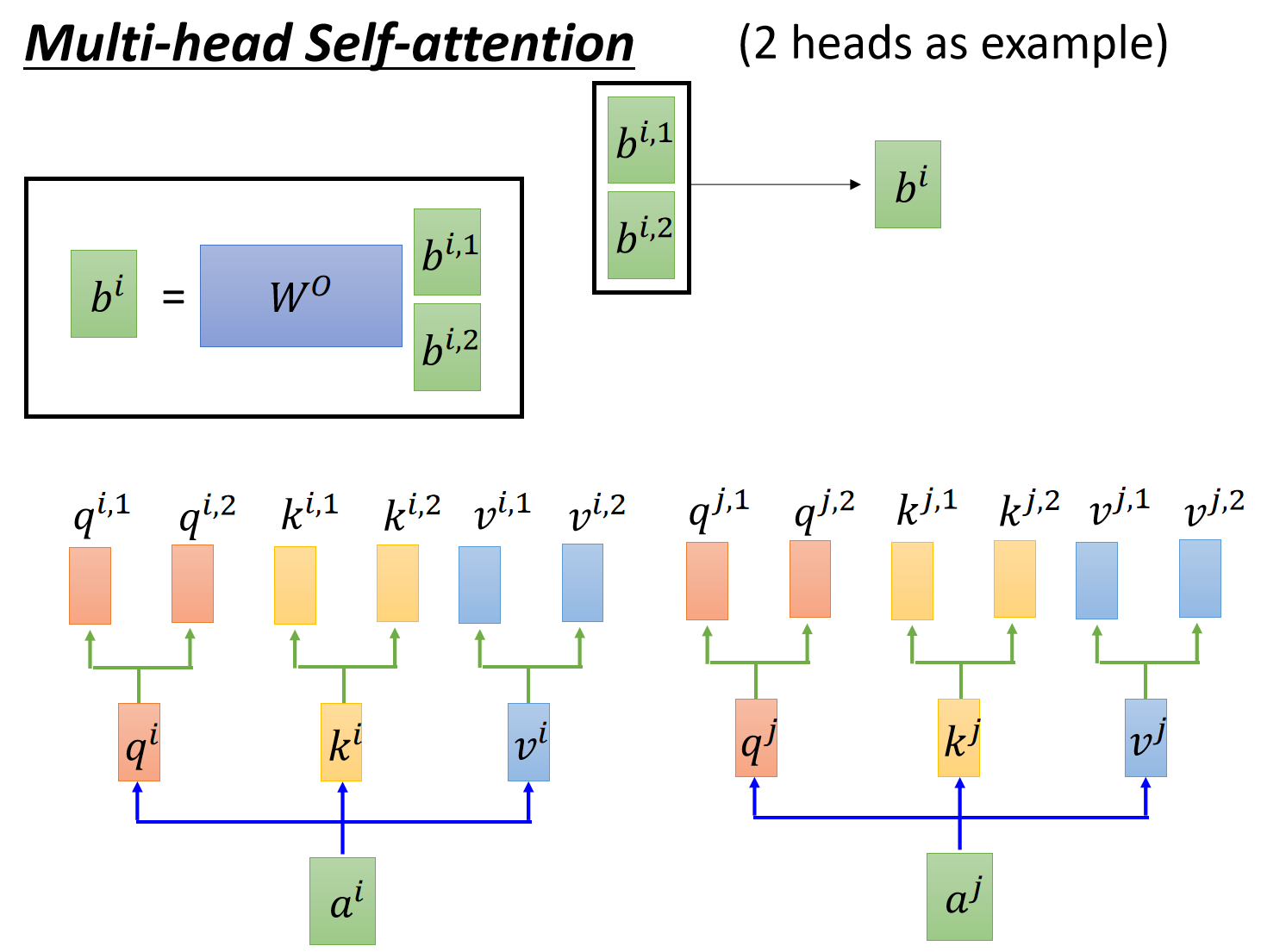
encoder
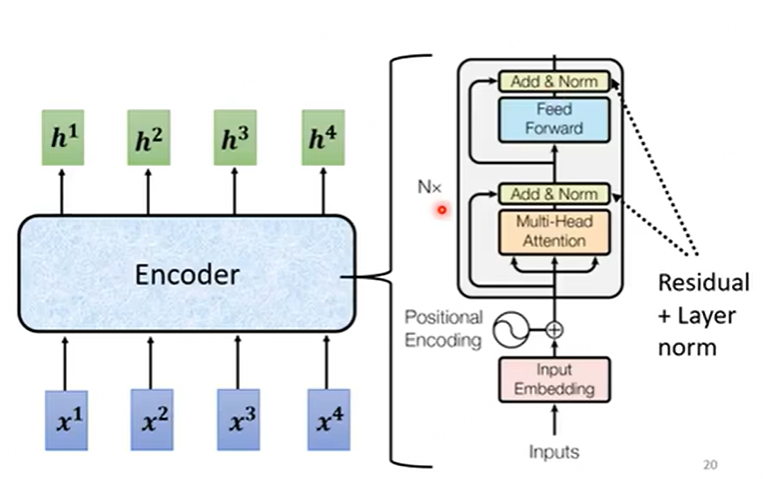
encoder输入还会考虑一个位置编码,一起嵌入到Embedding表示后的token中。
整个计算过程也很直观
decoder
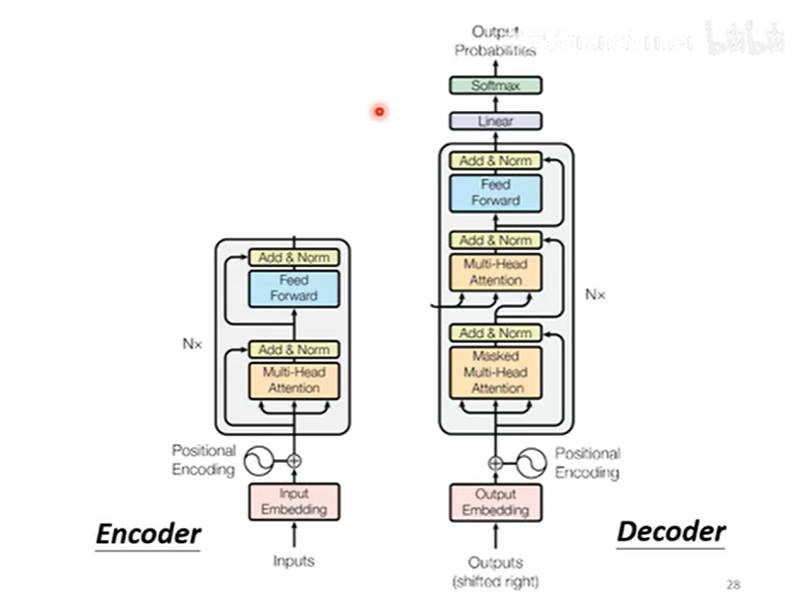
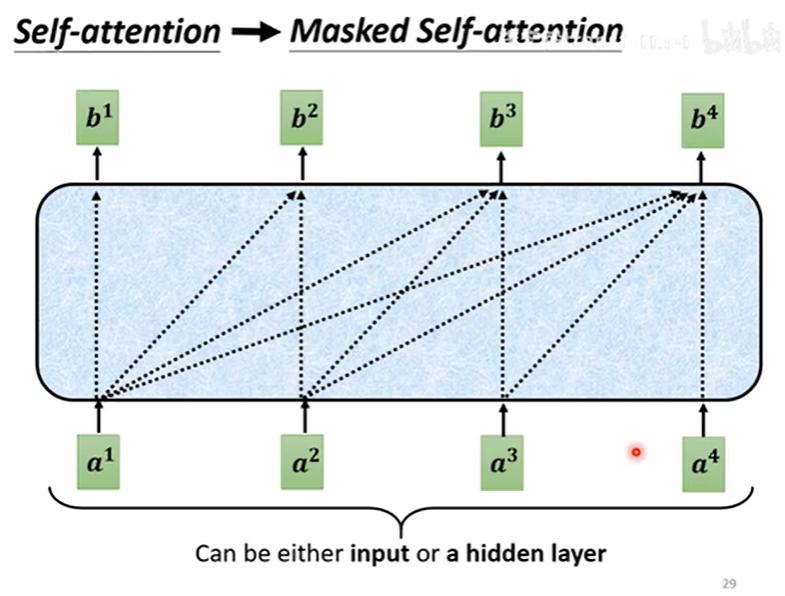
这里有一个很关键的点是,在encoder中只有self-attention,因为是一次性输入所有的token,计算每个token之间的关联性,得到一个编码后的输出。但是decoder是一个一个输入,每输入一个产生一个输出,虽然说这一步也可以用矩阵并行计算,其原理就是masked-attention。计算
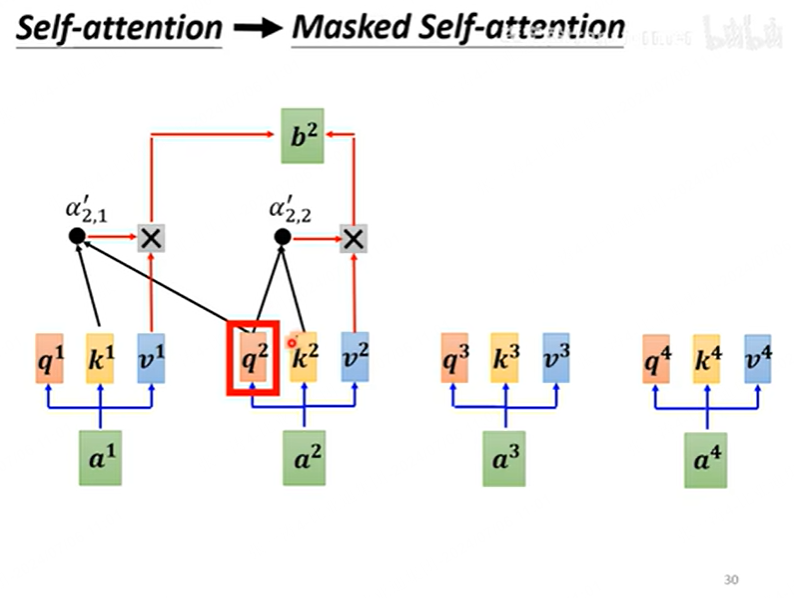
值得注意的是,在decoder中mask-attention后的输出,还会和encoder的输出再作一次attention,这被称为cross-attention。self-attention是同一个序列计算得分,而cross-attention是两个不同序列计算得分。
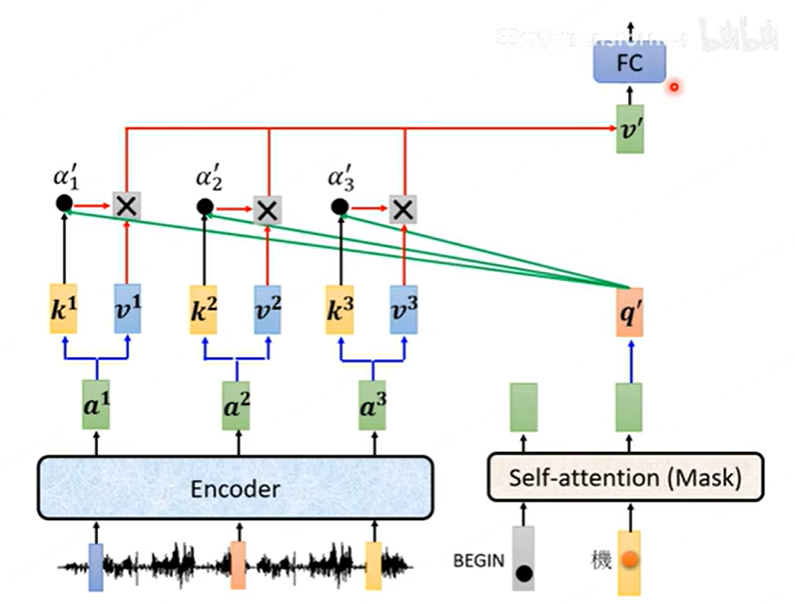
总结一下,encoder输入src序列,docoder输入target序列,最后将decoder的输出和target序列作一个cross entropy,优化的目标就是两个分布越接近越好。其实这一步可以看成一个分类,而类别就是词汇表的单词的总数?